TensorFlow LSTM Attention 机制图解
深度学习的最新趋势是注意力机制。在接受采访时,现任OpenAI研究主管的Ilya Sutskever提到,注意力机制是最令人兴奋的进步之一,他们在这里进行投入。听起来令人兴奋但是什么是注意机制?
基于人类视觉注意机制,神经网络中的注意机制非常松散。人的视觉注意力得到了很好的研究,虽然存在着不同的模式,但它们基本上都是以“低分辨率”感知周围的图像,以“高分辨率”的方式集中在图像的某个区域,然后随着时间的推移调整焦点。
注意力机制解决什么问题?
为了理解我们可以做什么,我们以神经机器翻译(NMT)为例。传统的机器翻译系统通常依赖于基于文本统计属性的复杂特征工程。简而言之,这些系统是复杂的,并且大量的工程设计都在构建它们。神经机器翻译系统工作有点不同。在NMT中,我们将一个句子的含义映射成一个固定长度的向量表示,然后基于该向量生成一个翻译。通过不依赖于n-gram数量的东西,而是试图捕捉文本的更高层次的含义,NMT系统比许多其他方法更广泛地推广到新句子。也许更重要的是,NTM系统更容易构建和训练,而且不需要任何手动功能工程。事实上,Tensorflow中的一个简单的实现不超过几百行代码。
大多数NMT系统通过使用循环神经网络将源语句(例如,德语句子)编码为向量,然后基于该向量来解码英语句子,也使用RNN来工作。
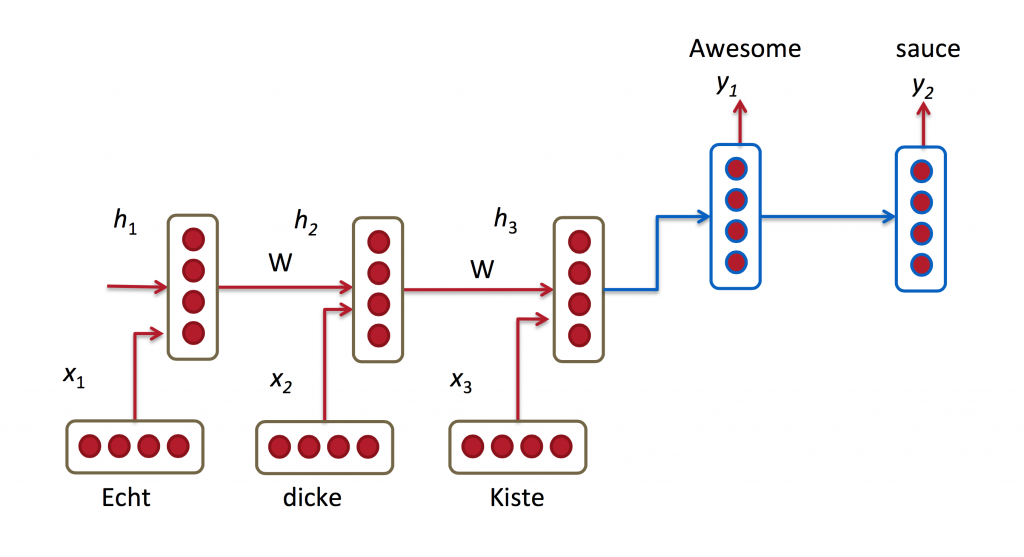
在上述图中,将“Echt”,“Dicke”和“Kiste”字馈送到编码器中,并且在特殊信号(未示出)之后,解码器开始产生翻译的句子。解码器继续生成单词,直到产生句子令牌的特殊结尾。这里,h向量表示编码器的内部状态。
如果仔细观察,您可以看到解码器应该仅基于编码器的最后一个隐藏状态(上面的h_3)生成翻译。这个h3矢量必须编码我们需要知道的关于源语句的所有内容。它必须充分体现其意义。在更技术术语中,该向量是一个嵌入的句子。事实上,如果您使用PCA或t-SNE绘制不同句子在低维空间中的嵌入以降低维数,您可以看到语义上类似的短语最终彼此接近。这太棒了
然而,假设我们可以将所有关于潜在的非常长的句子的信息编码成单个向量似乎有些不合理,然后使解码器仅产生良好的翻译。让我们说你的源语句是50个字。英文翻译的第一个词可能与源句的第一个字高度相关。但这意味着解码器必须从50个步骤前考虑信息,并且该信息需要以矢量编码。已知经常性神经网络在处理这种远程依赖性方面存在问题。在理论上,像LSTM这样的架构应该能够处理这个问题,但在实践中,远程依赖仍然是有问题的。例如,研究人员已经发现,反转源序列(向后馈送到编码器中)产生明显更好的结果,因为它缩短了从解码器到编码器相关部分的路径。类似地,两次输入输入序列也似乎有助于网络更好地记住事物。
我认为把句子颠倒一个“黑客”的做法。它使事情在实践中更好地工作,但这不是一个原则性的解决方案。大多数翻译基准都是用法语和德语来完成的,与英语非常相似(甚至中文的单词顺序与英语非常相似)。但是有一些语言(如日语),一个句子的最后一个单词可以高度预测英语翻译中的第一个单词。在这种情况下,扭转输入会使事情变得更糟。那么,有什么办法呢?注意机制
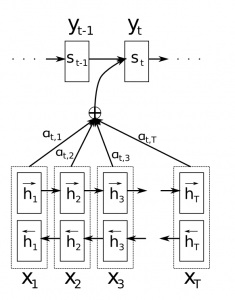
使用注意机制,我们不再尝试将完整的源语句编码为固定长度的向量。相反,我们允许解码器在输出生成的每个步骤“参加”到源句子的不同部分。重要的是,我们让模型基于输入句子以及迄今为止所产生的内容,学习了要注意的内容。所以,在很好的语言(如英语和德语)中,解码器可能会顺序地选择事情。在制作第一个英文单词时参加第一个单词,等等。这是通过联合学习来整合和翻译的神经机器翻译所做的,看起来如下:
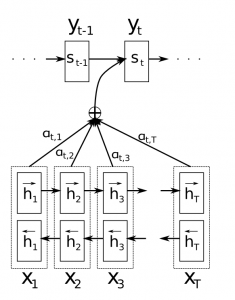
在这里,y是我们由解码器产生的翻译词,x是我们的源语句。上图说明使用双向循环网络,但这并不重要,您可以忽略反向方向。重要的部分是每个解码器输出字y_t现在取决于所有输入状态的加权组合,而不仅仅是最后一个状态。 a的权重定义为每个输出应考虑每个输入状态的多少。所以,如果a_ {3,2}是一个大数字,这意味着解码器在产生目标句子的第三个单词时,对源语句中的第二个状态给予了很大的关注。 a通常被归一化为总和为1(因此它们是输入状态的分布)。
关注的一大优点在于它使我们能够解释和可视化模型正在做什么。例如,通过在翻译句子时可视化注意力矩阵a,我们可以了解模型的翻译方式:

原文链接:http://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/
更多 Tensorflow 教程:http://www.tensorflownews.com/

